




This Community Spotlight was provided by Scott Young, Jason Clark, Patrick OBrien, and Kenning Arlitsch, Montana State University.
Discussions of building the digital library have centered around using tools like CONTENTdm and Solr/Blacklight to build local search interfaces for our digital content. This model has served us well, as the practice of creating locally-stored search indexes remains an industry best practice. However, as techniques for making digital collections findable on the open web have evolved, the work of optimizing data and following Search Engine Optimization (SEO) best practices has introduced new workflows and pressures to digital library development. In this post, we will explore how Google Custom Search can be incorporated and utilized to provide an effective and efficient alternative search index for digital collections.
Creating Indexable Content for Local Digital Collections Search Implementations AND Search Engines
At the core of digital library work is the act of creating indexable content. Libraries have many tools at our disposal to make this happen. Tools such as CONTENTdm provide a place to store metadata about digitized objects while also allowing users to query this data store to find matches. Indexable data and metadata represents the foundational data that will be served to search engines. This foundation is so crucial that the creation of indexable content becomes a given cost for developing digital libraries. In the pursuit of establishing such a fundamental requirement, one may choose from a number of tools and resources. Our recent research at the Montana State University Library has involved exploring the mechanics and principles of white hat SEO. Through the course of this research we have identified four primary components that strongly contribute to the successful harvesting of digital library collections by commercial search engines. These components include:
- Item level pages with rich metadata, generated dynamically
- A working site map listing all items registered within an individual Google Webmaster Tools profile
- A navigable website that provides simple paths to digital objects without any systems or design barriers to crawlers
- Schema.org markup or annotations to identify web page elements and categories on item level pages
The advantage of this work is twofold: digital library collections are surfaced in search engine results and, once indexed, these digital library collection indexes can be repurposed by using the Google Custom Search API to build digital library search solutions that are relatively easy to implement.
Current Search Solutions and Indexing Options: Costs, Benefits, and Alternatives
Blacklight has emerged in recent years as an impressive tool for accessing digital library materials through the web. Developed principally by the University of Virginia and Stanford University, Blacklight provides a range of capabilities that include faceted browsing, stable URLs, and relevancy ranking. In utilizing the powerful but complex Apache Solr search indexing platform, the Blacklight discovery interface represents a double-edged sword for digital librarians who wish to make the content of their library available through web search. Blacklight’s advanced utility is well documented, as is its high cost of implementation. The University of Hull, for example, pursued Blacklight with support of the UK funding agency Joint Information Systems Committee (JISC). A four-person team at the University of Hull completed an implementation of Blacklight over a seven-month period at a cost of £28,136 (approximately $44,000).
A recent digital library initiative at the Montana State University Library has involved creating a unified web search for our distributed digital collections databases.
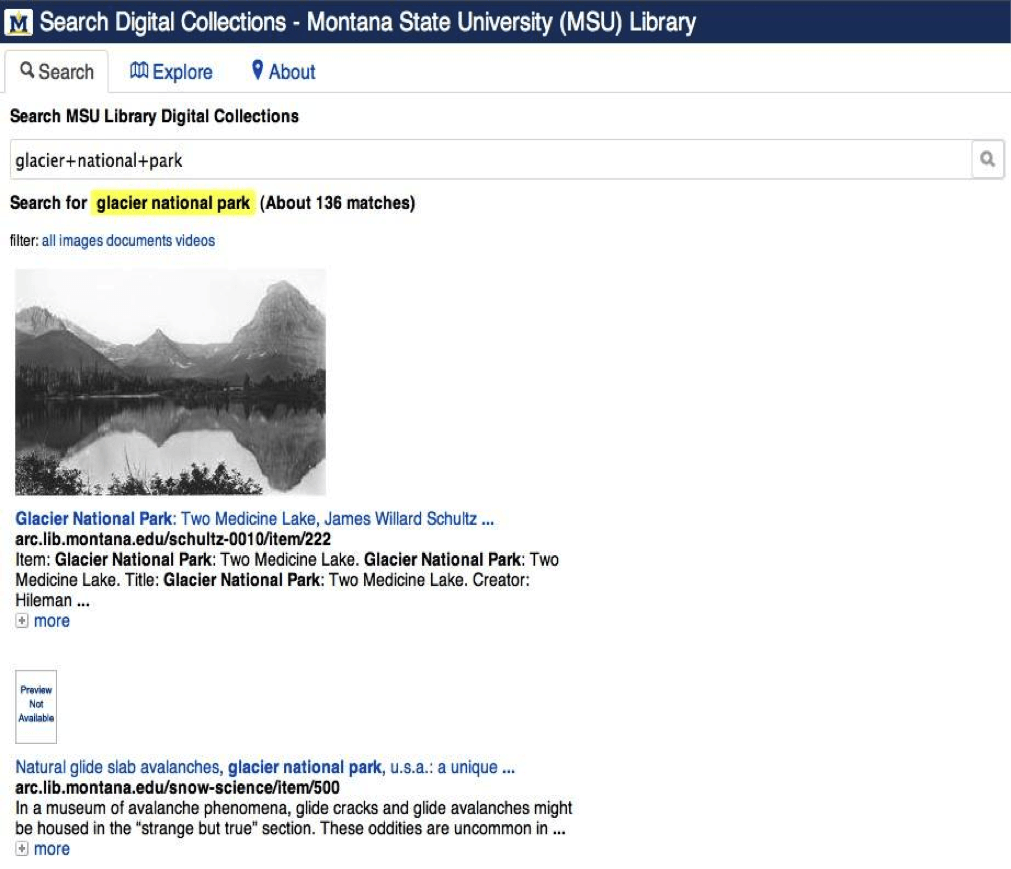
After exploring the complexities of Apache Solr indexing and determining that our staff could not reasonably dedicate sufficient resources to implementing Solr/Blacklight, we identified an alternative for indexing and discovery: Google Custom Search. Google Custom Search offers libraries powerful and flexible indexing for a range of content, including the images, documents, and videos that comprise digital library collections, without a significant upfront capital investment. The Google Custom Search service allows indexing capabilities similar to Apache Solr: faceted browsing, algorithm refinement, fast and scalable performance across large datasets, easy adjustment and tweaking of the search index, etc. No solution, however, is without costs. Google Custom Search, for its part, requires the following investment:
- An existing tool that can store metadata and produce indexable content via item level pages and site maps.
- Learning the Google Custom Search indexing requirements and API documentation.
- Discerning and following best practices for Schema.org markup.
- A pay-as-you-go subscription to the Google Custom Search service to allow for an extended query quota at the rate of $5 per 1000 queries, for up to 10,000 queries per day. (For MSU Library, we generously estimated 20,000 queries a month to our specific search index which would lead to about $1200 per year as a cost.)
Another path forward: Repurposing Google’s Search Engine Index for a Digital Collection Search Interface
In following a “metadata first” approach to digital library development, the MSU Library’s implementation of Google Custom Search has provided an increased understanding of the operations of commercial search engines that crawl and index our content. We have also been able to efficiently align digital library personnel in the work of building interoperable and indexable structured data markup following Schema.org best practices. And finally, we note the lowering of a significant barrier to creating a searchable collection index and the efficiencies gained in optimizing our digital library collections data for commercial search engines. In following this approach, we have been able to implement a faceted digital library collections search interface at a relatively low cost. Our preliminary research is showing promising results: building on Google’s search algorithm and indexing requirements using Google Custom Search provides an achievable alternative to other more complex indexing tools such as Apache Lucene or Apache Solr.
We will present a more detailed discussion of our research at this year’s DLF Forum in November 2013. We encourage you to join us there to learn and share more about the business case and implementation details for this method of building digital libraries.
Author Bios:
Jason Clark: Jason is the head of Digital Access and Web Services at Montana State University Library, where he builds library web applications and sets digital content strategies. You can find him online at http://jasonclark.info/ or on Twitter @jaclark.
Scott Young: As Digital Initiatives Librarian at Montana State University, Scott works to make information more open and accessible through front-end web development, semantic web development, user experience research, and social media. Catch up with him on Twitter @hello_scott_.
Patrick OBrien: Patrick is the Semantic Web Research Director at Montana State University Library.
Kenning Arlitsch: Dean of the Library at Montana State University. His book, co-authored with Patrick OBrien is titled Improving the Visibility and Use of Digital Repositories through SEO, and was published in February 2013. He occasionally tweets from @kenning_msu.